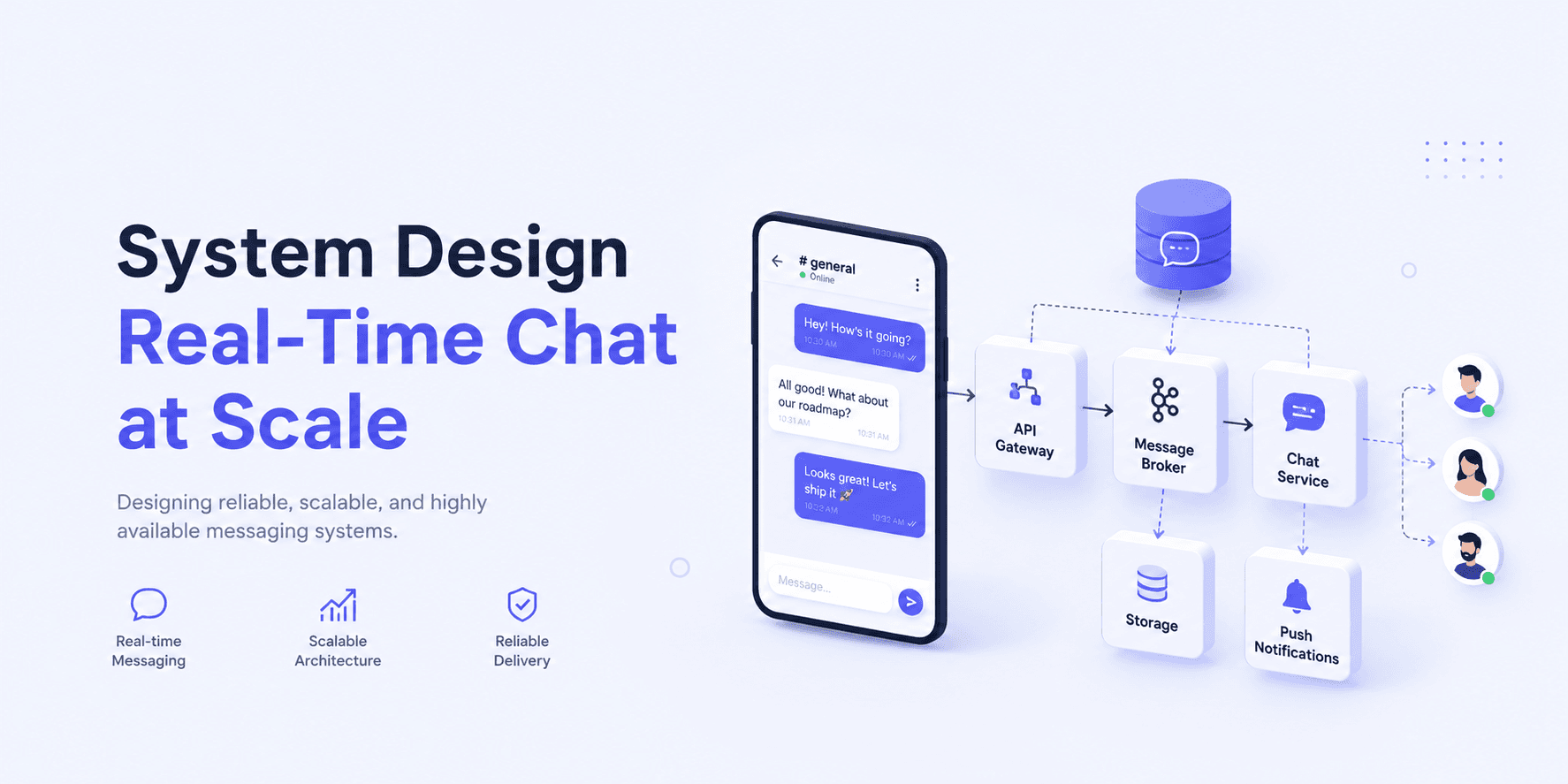
Client-Side Caching with LLMs: A Layered Decision Architecture for Cache Strategy under Uncertainty
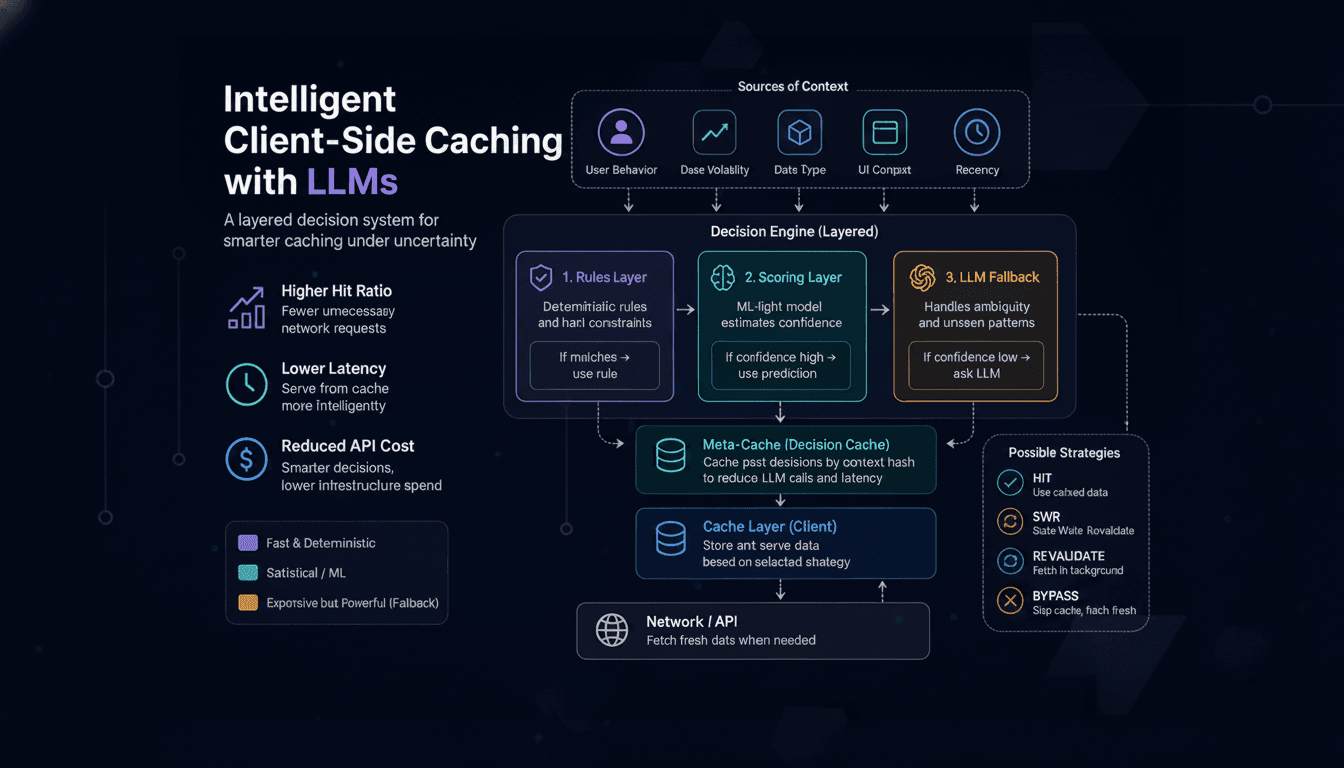
Client-side caching is commonly implemented as a storage optimization layer using TTLs and invalidation rules. In practice, caching behaves as a decision system under uncertainty, where correctness depends on data volatility, context, and user interaction patterns.
Static approaches break when data freshness is not uniform across the same application. This leads to either stale UI (over-caching) or excessive network requests (under-caching).
Problem: Caching is a Decision Problem, Not Storage
Client-side caching should be modeled as a policy engine:
data has different volatility profiles
freshness requirements depend on UI context
user interactions influence cache relevance
Typical volatility categories:
user profiles → low volatility
feeds / notifications → high volatility
search results → context-dependent volatility
partially hydrated UI → unknown volatility
The core issue is not caching mechanics, but missing decision logic for when and how to invalidate or reuse cached data.
Baseline Approaches in Client-Side Caching
1. SWR and TTL-based caching
Standard implementations (e.g. React Query, SWR) rely on:
stale-while-revalidate
background refetching
TTL-based invalidation
They perform well when:
data freshness is predictable
update cycles are stable
They fail when:
volatility varies within the same dataset
freshness depends on UI state or user context
2. Heuristic scoring systems
A more adaptive approach introduces computed cache policies:
volatilityScore = EWMA(changeFrequency)
priorityScore = userInteractionWeight * dataImportance
ttl = baseTTL / volatilityScore
Improvements:
adaptive cache lifetime
frequency-aware invalidation
Limitations:
requires manual feature engineering
weak generalization across domains
depends on complete signal observability
3. Lightweight ML models
Alternative approach using ML:
logistic regression
gradient boosting (XGBoost / LightGBM)
embedding-based classifiers
Advantages:
low latency inference
stable and predictable behavior
cheaper than LLM inference
Limitations:
requires labeled target (cache optimality is hard to define)
requires retraining pipelines
sensitive to product changes and distribution shifts
Why Traditional Approaches Plateau
All baseline systems assume:
feature space is complete
system dynamics are stationary
In real applications:
user behavior is contextual
volatility depends on UI state
“freshness importance” is semantic, not numeric
features are partially observable
This creates an upper bound for heuristic and ML-light approaches.
When LLMs Become Relevant
LLMs are not a replacement for caching systems.
They function as a fallback policy layer in ambiguous or under-specified decision space.
They are useful when:
feature confidence is low
signals conflict
unseen patterns appear
Layered Decision Architecture
The correct system design is hierarchical:
IF rule matches:
use deterministic policy
ELSE IF ML confidence high:
use ML policy
ELSE:
use LLM policy
This ensures:
deterministic execution dominates
ML handles structured uncertainty
LLM handles ambiguous cases only
System Architecture
UI Layer
↓
Context Builder
↓
Policy Engine
├── Rule Layer (fast path)
├── ML Scoring Model
└── LLM Fallback Engine
↓
Cache Layer
↓
Network Layer
Context Representation
All decisions are based on structured signals, not raw prompts:
{
"key": "user_feed",
"lastUpdatedMs": 1200,
"accessFrequency": "high",
"volatilityScore": 0.82,
"userAction": "scroll",
"stalenessToleranceMs": 500
}
Key constraint:
no free-form input
only deterministic feature structures
Role of LLM in the System
LLM output is constrained to classification:
{
"strategy": "HIT | REVALIDATE | BYPASS | SWR",
"ttlMs": 120000,
"confidence": 0.78
}
Meta-Cache Layer (Decision Caching)
To reduce LLM cost and latency variance:
decisionCache(contextHash) → cache strategy
Effects:
reduces repeated LLM inference
stabilizes decision latency
amortizes cost over repeated contexts
Cost-Aware Execution Model
Execution routing:
IF rule applies:
skip ML and LLM
ELSE IF ML confidence > threshold:
use ML model
ELSE:
use LLM
Typical distribution:
80–90% rule-based
10–20% ML-based
<10% LLM-based
Failure Modes and Mitigation
1. LLM overuse
Problem:
- increased cost
Mitigation:
strict confidence thresholds
deterministic routing priority
2. Latency variance
Problem:
- inconsistent response time
Mitigation:
decision caching
asynchronous precomputation
3. Model drift
Problem:
- degraded decision quality over time
Mitigation:
feedback loop
periodic recalibration of scoring model
Engineering Takeaways
caching should be modeled as a decision system
SWR and TTL cover most production cases
heuristic systems improve adaptivity but have limits
ML is optimal in structured, stable feature spaces
LLMs are only justified for ambiguity handling
production systems require layered routing
Key Conclusions
Client-side caching is fundamentally a policy optimization problem
No single approach (rules, ML, LLM) is sufficient alone
Hybrid architecture is required for production systems
LLMs should be strictly bounded to fallback scenarios
Decision caching is critical for cost and latency control
Key Takeaways
caching ≠ storage optimization, it is decision logic
most cases are solved by rules and SWR
ML is effective in structured domains with stable signals
LLMs are fallback systems for uncertain states
layered routing is required for stability and cost control