Why Your Background Jobs Are Lying to You
Most developers learn background jobs through a deceptively simple mental model:
Put a task into a queue.
A worker picks it up.
The task gets executed.
That’s it.
At least, that’s what we tell ourselves when we build our first async system.
Need to send an email? Throw it into a queue.
Generate a PDF? Queue.
Process images? Queue.
Queues feel like magic. They make slow operations disappear from your request-response cycle.
And for a while, everything works perfectly.
Then production happens.
A customer receives the same email four times.
A payment gets processed twice.
A report generation task disappears without a trace.
Workers suddenly spike to 100% CPU because thousands of jobs retry at once.
The system that was supposed to increase reliability becomes your biggest source of incidents.
And here’s the uncomfortable truth:
Background jobs are one of the most misunderstood parts of modern backend systems.
In this article, we’ll unpack what’s really going on behind queues — and how to design systems that don’t fall apart under real-world conditions.
The Happy Path Is a Lie
Let’s start with a familiar flow:
User Registration
↓
Create User
↓
Push Job to Queue
↓
Worker Picks Job
↓
Send Email
Looks clean. Predictable. Safe.
Most developers stop thinking here.
But distributed systems don’t live on the happy path.
Here’s what can actually go wrong:
Redis crashes right after pushing the job.
A worker crashes after sending the email.
The email provider responds too slowly.
The network drops mid-processing.
The worker finishes the task but fails to ACK.
Each of these creates a different failure mode.
And production systems hit these scenarios every day.
The key insight:
A queue does not guarantee execution. It only coordinates work.
Once you internalize this, your architecture starts to change.
At-Least-Once Delivery
Most queue systems operate with at-least-once delivery:
RabbitMQ
BullMQ
Sidekiq
AWS SQS
Kafka consumers
Celery
What this actually means:
Your job can run more than once.
Not exactly once. Not maybe once.
Multiple times.
Example:
Worker receives job
↓
Worker sends email
↓
Worker crashes
↓
No ACK sent
↓
Queue retries job
From the queue’s perspective, the job was never completed.
So it retries.
But the email was already sent.
Result? Duplicate emails.
This isn’t a bug.
This is expected behavior.
Idempotency Is Not Optional
Once you accept duplicate execution, one requirement becomes unavoidable:
Your jobs must be idempotent.
Bad example:
account.balance += 100;
Run twice → user gets $200.
Good example:
if (!processedTransactions.has(transactionId)) {
await creditAccount();
await markTransactionProcessed(transactionId);
}
Now duplicates are harmless.
This pattern applies everywhere:
Emails — store notification IDs.
Payments — use transaction IDs.
Orders — enforce unique references.
Webhooks — track processed events.
A more production-friendly version usually combines multiple protections:
async function processPaymentJob(job: { transactionId: string; userId: string; amount: number }) {
const alreadyProcessed = await db.paymentEvents.findUnique({
where: { transactionId: job.transactionId },
});
if (alreadyProcessed) return;
await db.$transaction(async (tx) => {
await tx.paymentEvents.create({
data: {
transactionId: job.transactionId,
userId: job.userId,
amount: job.amount,
},
});
await tx.accounts.update({
where: { userId: job.userId },
data: { balance: { increment: job.amount } },
});
});
}
The goal is not to prevent duplicate delivery.
The goal is to make duplicate delivery harmless.
The Myth of Exactly-Once
Sooner or later, every backend engineer asks:
Can I guarantee exactly-once processing?
Short answer: not really.
Failures can happen between any two steps:
Charge customer
↓
Success
↓
Save result in DB
If the service crashes in between:
Payment succeeded.
Database says it didn’t.
Now you have an inconsistent system.
“Exactly-once” in real systems usually means a mix of:
Deduplication
Idempotency
Checkpointing
Transaction logs
Atomic writes
Practical takeaway:
Design for duplicates. Don’t fight them.
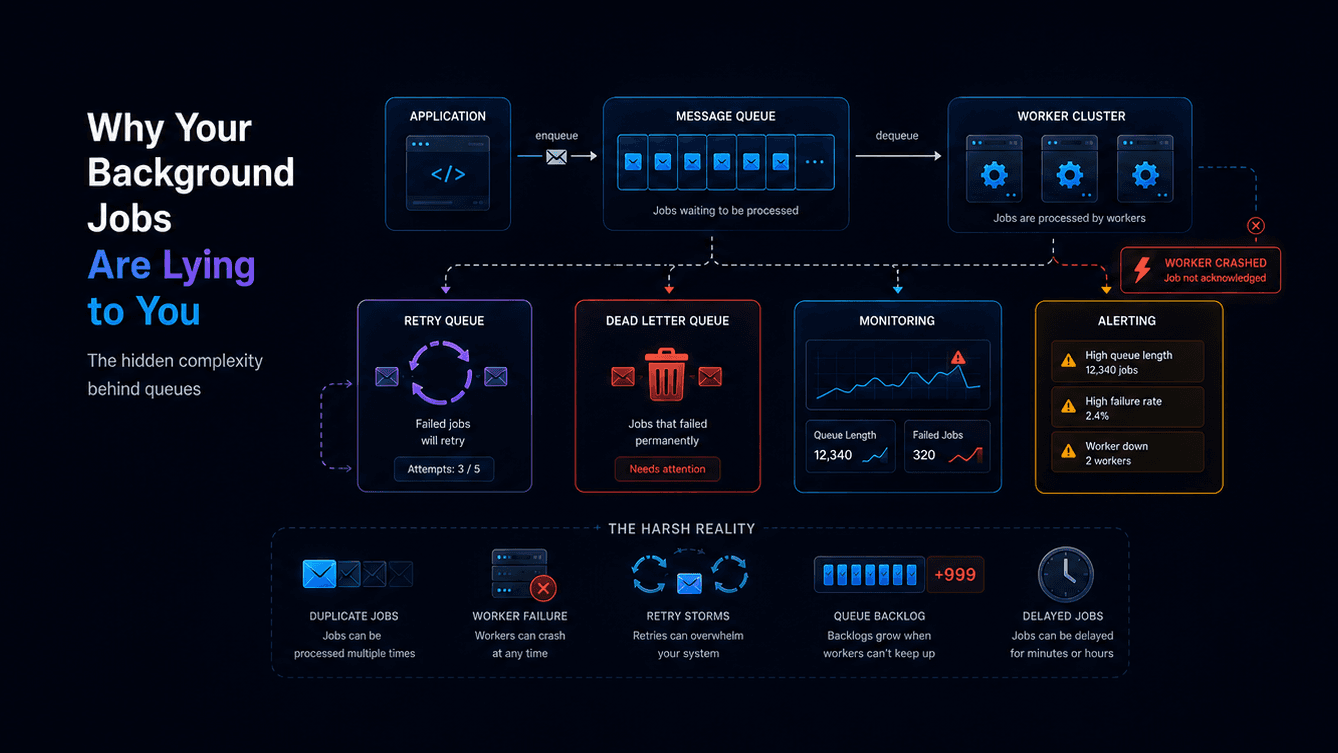
Retries Can Kill Your System
Retries sound harmless.
Until they aren’t.
Imagine:
You have 50,000 jobs.
A third-party API goes down.
Every job retries immediately.
Now you’ve created a retry storm.
Instead of helping recovery, you’re amplifying the outage.
Better approach: exponential backoff.
Example:
Retry #1 → 5 seconds
Retry #2 → 30 seconds
Retry #3 → 2 minutes
Retry #4 → 10 minutes
Retry #5 → 1 hour
Even better: add jitter.
Instead of synchronized retries, jobs spread out over time.
A practical pattern:
function getRetryDelay(attempt: number) {
const base = Math.min(60_000 * 2 ** attempt, 3_600_000);
const jitter = Math.floor(base * (0.5 + Math.random() * 0.5));
return jitter;
}
This is standard in large-scale systems for a reason.
Dead Letter Queues Save You
Some jobs are just broken:
Invalid payload
Missing data
Deleted resources
Validation errors
Retrying them forever is pointless.
Yet many systems do exactly that.
Solution: Dead Letter Queues (DLQ)
Main Queue
↓
Fails multiple times
↓
Dead Letter Queue
Benefits:
Cleaner monitoring
Lower infrastructure cost
Faster debugging
Predictable behavior
If your queue supports DLQ, enable it early.
Not later. Not “when needed.”
From day one.
Long Jobs Break Easily
A common anti-pattern:
One massive job doing everything:
Generate report
Download assets
Resize images
Upload files
Send email
Update DB
Looks efficient.
It’s not.
If step 5 fails, what do you do?
Re-run everything?
Risk duplicates?
Re-upload files?
Instead, break it down:
Generate Report
↓
Process Assets
↓
Upload Results
↓
Notify User
Benefits:
Easier retries
Better observability
Smaller failure scope
Independent scaling
Smaller jobs fail less catastrophically.
Monitoring Matters More Than Processing
Most teams:
Spend weeks building queues.
Spend zero time monitoring them.
That’s a mistake.
Track at least:
Queue length — are workers keeping up?
Processing latency — are jobs waiting too long?
Job duration — any unexpected spikes?
Failure rate — early signal of issues.
Retry volume — warning before incidents.
Without visibility, you’re debugging blind.
Backpressure Is the Silent Killer
If your system receives:
- 100 jobs/sec
But can process:
- 50 jobs/sec
You’re in trouble.
The backlog will grow forever.
Eventually:
Memory explodes.
Latency becomes unacceptable.
The system degrades.
This is backpressure.
Handle it with:
Rate limiting
Worker scaling
Priority queues
Load shedding
Every system has limits. Ignoring them is not a strategy.
What Production Systems Actually Look Like
What we imagine:
Queue → Worker → Done
Reality:
App
↓
Queue
↓
Workers
↓
Retry logic
↓
Dead Letter Queue
↓
Monitoring
↓
Alerting
Notice something?
Actual processing is the simplest part.
Most complexity is in handling failure.
A Quick Production Checklist
Before shipping any queue system:
Is the job idempotent?
Can it safely run multiple times?
Are retries using exponential backoff?
Is jitter enabled?
Is DLQ configured?
Are metrics in place?
Have failure scenarios been tested?
Can workers scale horizontally?
Is backpressure handled?
Are jobs small and composable?
If not, you're not production-ready yet.
Final Thought
Queues look simple because tutorials only show success paths.
Real systems deal with:
Crashes
Network failures
Duplicate messages
Out-of-order execution
Retry storms
And still need to work.
The key shift:
Background jobs aren’t about executing work. They’re about executing work reliably under constant failure.
Once you start thinking this way, your architecture changes.
And that’s when your queue system becomes something you can actually trust.