Designing a Real-Time Chat System at Scale
Most developers underestimate how difficult messaging systems actually are.
A basic chat demo with WebSockets can be built in a few hours. A production-grade messaging platform like WhatsApp, Telegram, Discord, or Slack is a completely different engineering problem. The hard part is not rendering messages in the UI; the hard parts are maintaining millions of persistent connections, delivering messages reliably, preserving ordering, handling offline synchronization, scaling group chats, surviving partial failures, and minimizing latency globally.
In this article, we'll design a scalable real-time messaging architecture and look at the trade-offs behind modern chat systems.
Requirements
Before discussing architecture, we need clear system requirements.
Functional requirements
Our messaging system should support:
One-to-one chats.
Group chats.
Real-time message delivery.
Read receipts.
Typing indicators.
Push notifications.
Media attachments.
Message history.
Multi-device synchronization.
Online and offline presence.
Non-functional requirements
The system must also provide:
Low latency.
High availability.
Horizontal scalability.
Fault tolerance.
Reliable delivery.
Event ordering.
Efficient storage.
Global distribution.
At small scale, these problems are trivial. At millions of users, every single one becomes a distributed systems problem.
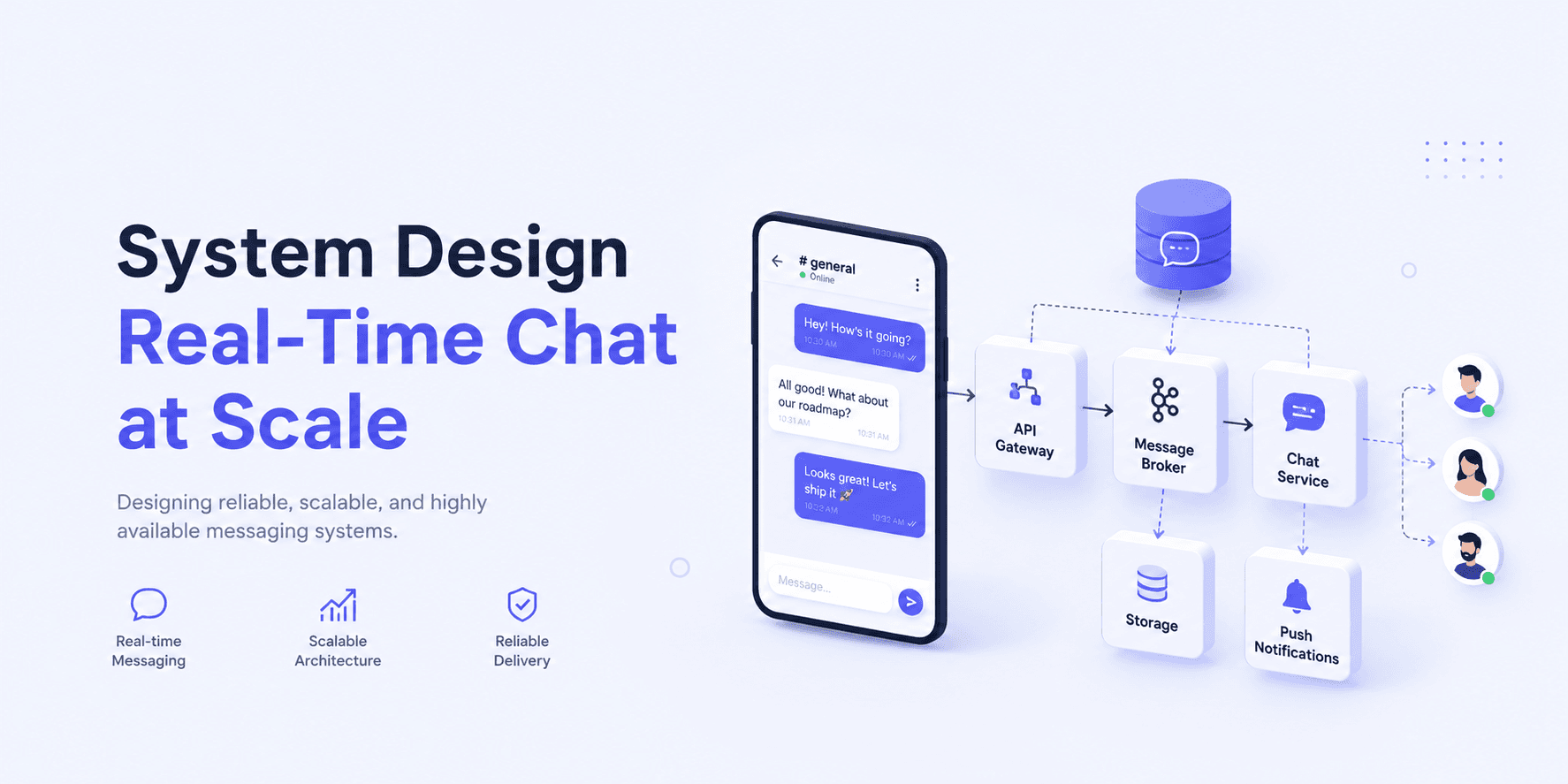
High-level architecture
A modern messaging platform is usually event-driven and distributed.
A simplified architecture looks like this:
Clients
↓
Load Balancer
↓
WebSocket Gateway Cluster
├── Authentication Service
├── Presence Service
├── Chat Service
├── Notification Service
└── Media Service
↓
Kafka / Redis Streams
↓
Storage Layer
Each component has a separate responsibility. This separation is critical for scalability.
Why polling fails
Many beginner chat applications start with polling.
GET /messages every 2 seconds
This works for demos. It fails badly at scale.
Polling creates:
Massive request overhead.
Unnecessary database reads.
Increased latency.
Battery drain on mobile devices.
Poor real-time responsiveness.
Imagine 2 million connected users polling every 2 seconds. That creates 1 million requests per second even when nobody sends messages. This is why real-world systems use persistent connections.
Why WebSockets became standard
WebSockets maintain a persistent bidirectional connection between client and server.
Benefits include:
Near real-time communication.
Lower overhead.
Reduced latency.
Efficient server push.
Better mobile performance.
The client establishes a connection once:
Client ───── persistent connection ───── Server
After that, both sides can exchange events instantly. This is the foundation of modern messaging systems.
The hidden WebSocket cost
WebSockets solve one problem while introducing another.
Persistent connections consume server memory. Every connected user occupies:
TCP socket.
Memory buffers.
Heartbeat state.
Authentication context.
Handling 5 million concurrent users is no longer a simple API problem. It becomes a connection management problem. This is why messaging companies build specialized gateway infrastructure.
WebSocket gateway layer
The gateway layer is responsible for:
Maintaining persistent connections.
Authenticating users.
Routing events.
Managing heartbeats.
Detecting disconnects.
Gateways should remain as stateless as possible. Stateless gateways are easier to scale, replace, and recover after failures.
Authentication flow
A common flow looks like this:
User logs in via HTTP.
Backend issues a JWT token.
Client opens a WebSocket connection.
Token is validated during handshake.
Connection is associated with a user session.
Example:
wss://chat.example.com?token=JWT
After authentication, the gateway knows which user owns the connection.
Sending a message
Now let's examine the real delivery pipeline.
Suppose User A sends:
Hello
A simplified flow is:
Client sends a message event.
Gateway validates authentication.
Chat service validates permissions.
Message is persisted in durable storage.
Event is published into Kafka.
Recipient gateway receives the event.
Message is pushed to the recipient.
Delivery ACK is generated.
Read receipt is generated later.
This pipeline sounds simple. In reality, every step contains failure scenarios.
Why persistence comes first
Many beginners try this approach:
deliver → save later
That is dangerous.
If the server crashes before persistence, the recipient saw the message but the database lost it. Now your system is inconsistent. Production systems usually do:
persist → publish → deliver
Durability comes first.
Message IDs and ordering
Distributed systems do not guarantee ordering automatically.
Example:
Message A.
Message B.
Recipient receives:
Message B.
Message A.
Why? Because messages may travel through different gateway servers, queues, and network paths. Ordering becomes difficult at scale.
Common ordering strategies
Timestamp ordering
Simple, but unreliable. Clock drift breaks consistency.
Incremental sequence IDs
More reliable.
Example:
conversation_id: 42
messages:
1
2
3
4
This guarantees ordering inside a conversation. Most real systems only guarantee local ordering per chat. Global ordering across the entire platform is usually impossible at scale.
Database design
Messaging systems are write-heavy. A single popular group chat may generate thousands of writes per second.
Typical tables:
usersconversationsconversation_membersmessagesmessage_statusattachments
The real challenge is partitioning.
Why single database servers eventually fail
A single PostgreSQL instance works initially. Eventually, these problems appear:
Write bottlenecks.
Storage growth.
Replication lag.
Index size explosion.
At scale, systems introduce sharding.
Sharding strategy
One common strategy is:
shard by conversation_id
Benefits:
Messages for the same chat remain colocated.
Ordering becomes easier.
Queries stay efficient.
Bad shard keys create catastrophic hotspots. For example, sharding by user_id can spread large group chats across many shards and make fan-out expensive.
Kafka and event streaming
Modern messaging systems are heavily event-driven.
Kafka is often used because it provides:
Durable event logs.
Replayability.
Partitioned scalability.
Consumer groups.
Instead of services calling each other directly:
Chat Service → Kafka → Consumers
Consumers may include:
Delivery service.
Notification service.
Analytics.
Moderation.
Push notifications.
This decouples the architecture and makes failures easier to isolate.
Presence system
Presence is deceptively expensive.
Tracking online, offline, typing, and last_seen for millions of users creates enormous event traffic. Most systems isolate presence into a dedicated service.
Presence implementation
A common architecture is:
Gateway → Redis → Presence Service
Gateways periodically send heartbeats. Example:
PING every 30 seconds
If heartbeats stop, the user is marked offline.
Redis works well because presence data is ephemeral. Not everything belongs in a relational database.
Typing indicators
Typing indicators look trivial. They are not.
Problems include:
High event frequency.
Noisy updates.
Unnecessary fan-out.
Most systems heavily throttle typing events. Example:
User typing → emit once every 3 seconds
Without throttling, typing indicators can overload infrastructure faster than messages themselves.
Fan-out in group chats
Suppose a group contains 500,000 users.
One message may require 500,000 deliveries. This is called fan-out.
Large fan-out is one of the hardest messaging problems.
Fan-out strategies
Fan-out on write
The server precomputes deliveries immediately.
Fast reads.
Expensive writes.
Fan-out on read
Messages are stored once.
Cheaper writes.
More expensive reads.
Different platforms choose different trade-offs.
Offline synchronization
Users disconnect constantly:
Mobile app closed.
Network loss.
Airplane mode.
Battery saver.
The system must synchronize missed events efficiently.
Typical approach:
fetch all events after last_sequence_id
Example:
last_seen_message = 10451
Server returns:
10452+
Incremental synchronization is critical. Full synchronization is too expensive.
Push notifications
Offline users still need notifications.
Pipeline:
message event
↓
notification service
↓
APNs / FCM
↓
mobile device
Push systems are eventually consistent. Notifications may arrive late, duplicated, or out of order. Clients must tolerate inconsistencies.
Multi-device sync
Modern users expect synchronization across:
Phone.
Desktop.
Browser.
Tablet.
Each device may maintain its own session. The backend tracks:
user_iddevice_idconnection_idlast_sync_state
Events are usually delivered independently per device.
Reliability guarantees
Messaging systems must define delivery semantics.
At-most-once
Fastest. Messages may disappear.
At-least-once
Reliable. Duplicates are possible.
Exactly-once
Extremely expensive and difficult in distributed systems.
Most production systems use:
at-least-once + idempotency
This is the practical engineering choice.
Why exactly-once is mostly marketing
Exactly-once delivery across distributed infrastructure is incredibly difficult.
Network failures create ambiguity:
Did the recipient receive the message?
Did the ACK get lost?
Did the retry create a duplicate?
Sometimes the sender cannot know. This is why many systems rely on retries, deduplication, and idempotent consumers instead of true exactly-once guarantees.
Common failure scenarios
Real systems fail constantly.
Examples:
Gateway crashes.
Kafka partition unavailable.
Redis outage.
Slow consumers.
Duplicate events.
Partial synchronization.
Network splits.
Reliable systems assume failure is normal.
Scaling strategies
As traffic grows, teams usually add:
Horizontal scaling for gateway nodes.
Partitioned Kafka topics.
Regional infrastructure.
CDN for media.
Caching to reduce database pressure.
The biggest bottleneck is usually not CPU.
At scale, bottlenecks are often:
Network throughput.
Memory usage.
Hot partitions.
Connection limits.
Disk I/O.
Replication lag.
Chat systems are infrastructure-heavy workloads.
What makes messaging hard
The frontend UI may look simple. Underneath is a distributed system balancing:
Consistency.
Availability.
Latency.
Reliability.
Scalability.
Every architectural decision introduces trade-offs. You can optimize latency, durability, throughput, or cost, but rarely all at once.
That is why messaging systems remain one of the most interesting areas in system design.
Practical takeaway
If you are building chat, do not think only in terms of sockets and message lists. Think in terms of delivery guarantees, storage strategy, ordering, recovery, and fan-out.
A chat product becomes serious very quickly. The moment you need offline sync, presence, multi-device support, and reliable delivery, you are no longer building a UI feature — you are building a distributed messaging platform.