Real-Time Notification Systems Are Harder Than Most Teams Expect (And How to Build Them Right)

What you'll learn:
Why "just send a WebSocket event" fails in production
The exact failure modes and their root causes
Concrete patterns for delivery semantics, ordering, and deduplication
An operational playbook with metrics, alerts, and runbook steps
A real incident story with timeline, root cause, and fix
Who this is for: Senior/mid backend engineers building real-time systems at scale (10k+ users)
Most developers think notifications are a solved problem
"Just send a WebSocket event."
That assumption survives until the first production incident. Then reality appears:
duplicate notifications
lost events
race conditions
users receiving messages hours late
mobile devices silently disconnecting
Kafka lag spikes
Redis memory explosions
retry storms
notification ordering breaking across regions
Real-time systems fail in ways that look random while actually being deterministic consequences of architecture decisions made months earlier.
Unlike ordinary backend bugs, notification failures are immediately visible to users. Users tolerate slow analytics dashboards. They do not tolerate:
missing payment alerts
delayed security notifications
duplicated chat messages
phantom unread counters
alerts arriving after the action is already completed
This is why notification infrastructure becomes one of the most operationally expensive systems in modern products. Not because sending events is difficult. Because guaranteeing delivery semantics at scale is difficult.
Delivery Semantics Taxonomy: Choose Your Guarantees First
Before designing, you must choose your delivery semantics based on product requirements:
| Semantics | Description | When to use | Trade-off |
|---|---|---|---|
| At-most-once | May lose messages, no duplicates | Non-critical alerts (e.g., feed updates) | Lowest latency, highest risk of loss |
| At-least-once | May duplicate, never lose | Payment/security alerts | Must handle duplicates via deduplication |
| Effectively-once | Deduplication via idempotency keys | Critical state updates (e.g., "payment refunded") | Requires storage of idempotency keys |
Ordering guarantees:
Global ordering: Extremely expensive (requires single partition), rarely needed
Per-user ordering: Sweet spot for most apps (key by
user_id)Per-conversation ordering: Chat/messaging systems (key by
conversation_id)Causal ordering: Advanced (track causality with version vectors)
Durability:
In-memory: Fast, loses state on crash
Persisted (WAL): Slow but recoverable (write-ahead log)
Compacted: Retains only latest state (Kafka compaction)
Client sync model:
Push-only: Simple, unreliable on mobile
Push+pull: Hybrid with durable cursors (recommended)
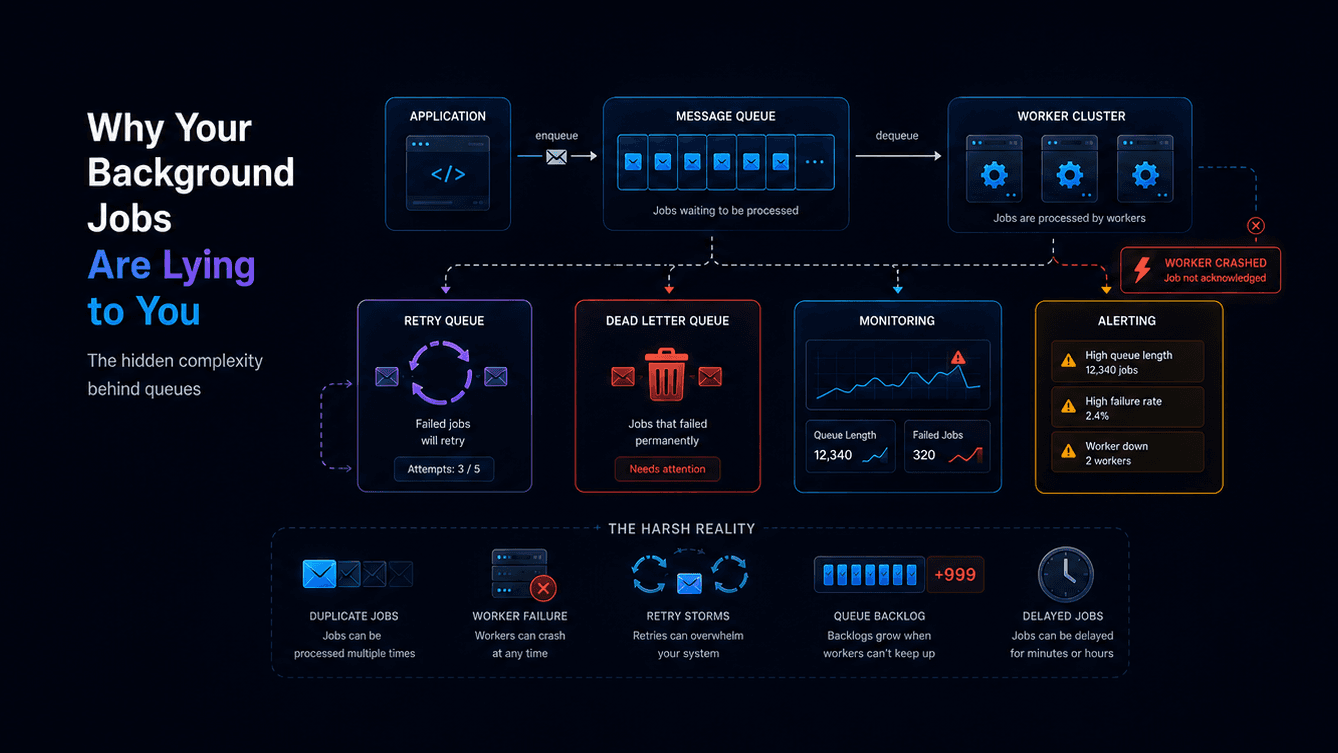
The Naive Architecture Everyone Starts With
Most systems begin like this:
Backend → WebSocket Server → Client
Simple. Fast. Works locally.
Then production traffic arrives. Now you suddenly need to handle:
reconnects
retries
offline users
multi-device sync
message persistence
event ordering
fan-out
push notifications
email fallback
throttling
deduplication
distributed state
The architecture quietly transforms into this:
Services
↓
Event Bus (Kafka/RabbitMQ/NATS)
↓
Notification Workers
↓
Delivery Pipeline
↓
WebSocket Gateway Cluster
↓
Clients
And even this is still incomplete. Because the real system is not transport. The real system is state consistency under unreliable networks.
WebSockets Solve Transport, Not Reliability
This is the mistake many junior and mid-level teams make.
WebSockets provide:
low latency
bidirectional communication
persistent connection
WebSockets do NOT provide:
guaranteed delivery
ordering guarantees
reconnection recovery
deduplication
persistence
backpressure handling
A disconnected client loses messages unless the backend stores replayable state. So production systems evolve toward:
event logs
sequence numbers
resumable streams
idempotent consumers
acknowledgement protocols
At this point, the "notification system" starts resembling a distributed messaging platform. Because that is exactly what it became.
The Real Enemy Is Fan-Out
Sending one event to one client is trivial. Sending one event to 10,000 users across multiple regions with device-specific preferences while preserving ordering under retry conditions is a completely different engineering problem.
Fan-out changes system behavior dramatically.
Example: A single social media post may generate:
feed updates
push notifications
email digests
badge counter updates
recommendation recalculations
analytics events
moderation triggers
One action becomes dozens of downstream events. This creates:
cascading retries
queue amplification
traffic spikes
hot partitions
uneven load distribution
The infrastructure problem is no longer messaging. It becomes traffic shaping.
Root Cause: How Consumer Group Rebalancing Creates Duplicates
Scenario:
1. User message emitted to Kafka partition 0
2. Consumer A processes message, sends via WebSocket
3. Consumer A crashes BEFORE committing offset
4. Consumer group rebalances, Consumer B takes over partition 0
5. Consumer B reprocesses same message (offset not committed)
6. User receives duplicate notification
Root cause: At-least-once semantics + no offset commit before processing
Fix: Store idempotency key + deduplicate at consumer layer
Most Notification Systems Eventually Need Event-Driven Architecture
At small scale:
API → send notification
At scale:
API → emit domain event → async processing
That distinction matters. Because tightly coupling notification delivery to request lifecycle creates:
higher latency
cascading failures
deployment coupling
retry complexity
Modern systems increasingly move toward:
Kafka
NATS
RabbitMQ
Redis Streams
event sourcing patterns
Not because they are trendy. Because synchronous notification pipelines eventually become operational bottlenecks.
Ordering Is More Expensive Than Throughput
Many teams optimize for throughput first. But users notice ordering bugs faster than latency.
Receiving "Payment refunded" before "Payment received" destroys trust instantly.
Ordering becomes especially painful in:
multi-region deployments
partitioned event streams
horizontally scaled consumers
retry-based delivery systems
Global ordering is extremely expensive. Most large systems eventually settle for:
per-user ordering (key by
user_id)per-conversation ordering (key by
conversation_id)causal consistency
approximate ordering
Because strict global ordering at scale often destroys performance.
Implementation: Per-User Ordering with Sequence Numbers
# Per-user append-only log with sequence numbers
class NotificationLog:
def __init__(self, user_id):
self.user_id = user_id
self.sequence = 0
def append(self, notification):
self.sequence += 1
record = {
"user_id": self.user_id,
"sequence": self.sequence,
"notification": notification,
"idempotency_key": f"{self.user_id}:{self.sequence}"
}
# Write to Kafka with user_id as partition key
kafka.produce(topic="notifications", key=self.user_id, value=record)
return record
def deliver_with_dedupe(self, notification, idempotency_key):
if redis.exists(f"dedupe:{idempotency_key}"):
return # Already delivered
redis.setex(f"dedupe:{idempotency_key}", 24*3600, "1")
self.append(notification)
Mobile Devices Make Everything Worse
Desktop browsers are relatively stable. Mobile clients are chaos.
Problems include:
background process killing
aggressive battery optimization
flaky network transitions
push delivery delays
silent disconnects
OS-level throttling
This is why production notification systems usually combine:
WebSockets (for desktop/active mobile)
APNs (iOS push)
FCM (Android push)
polling fallbacks (for when push fails)
local persistence (client-side cache)
sync checkpoints (resume from last seen sequence)
The system becomes hybrid by necessity. Pure real-time delivery is unreliable on mobile networks.
APNs/FCM Reality Check
APNs and FCM do NOT guarantee delivery:
Notifications can be dropped under battery optimization
Coalescing: multiple notifications merged into one
Token expiration: devices regenerate push tokens
Rate limiting: Apple/Google throttle excessive pushes
Always implement:
Push token refresh logic
Fallback to WebSocket/polling if push fails
Server-side message persistence for offline users
Real Incident Story: Duplicate Payment Alerts at 3AM
Timeline:
03:12 AM: User reports receiving 47 "Payment confirmed" emails in 2 minutes
03:15 AM: On-call engineer alerts triggered (retry rate spiked to 34%)
03:18 AM: Found Kafka consumer lag at 120k messages (normally <500)
03:25 AM: Root cause identified: Consumer worker crashed mid-batch, offset not committed
03:30 AM: Hotfix deployed: Added idempotency key check before sending
04:00 AM: System stabilized, duplicate rate dropped to 0.02%
Root cause:
Producer retries on timeout → Kafka received duplicate messages
Consumer processed duplicates → No idempotency check at sender layer
Email service sent 47 emails → Rate limiter bypassed due to batch processing
Fix implemented:
# Before (buggy):
def send_notification(notification):
email_service.send(notification) # No deduplication
consumer.commit() # Commit AFTER sending = duplicates on crash
# After (fixed):
def send_notification(notification):
idempotency_key = f"{notification.user_id}:{notification.sequence}"
if redis.exists(f"dedupe:{idempotency_key}"):
consumer.commit() # Already processed, just commit
return
email_service.send(notification)
redis.setex(f"dedupe:{idempotency_key}", 24*3600, "1")
consumer.commit() # Commit AFTER dedup check + send
Lessons learned:
Always commit offsets after processing completes
Idempotency keys must be checked before side effects (email, push)
Monitor consumer lag with p99 alerts (not just average)
Batch processing needs per-item deduplication, not per-batch
Observability Becomes Critical
Without observability, notification systems become impossible to debug.
You need visibility into:
queue lag (Kafka/RabbitMQ)
dropped events
retry counts
connection churn
fan-out latency
consumer health
delivery success rates
And most importantly:
Can we prove the user received the notification?
Not:
Did we send it?
Those are different questions. A successful Kafka publish does not mean:
the WebSocket gateway processed it
the client received it
the UI rendered it
the user saw it
Real observability requires end-to-end tracing across the entire delivery pipeline.
Operational Playbook: Metrics, Alerts, Runbook
Key metrics to track:
| Metric | Threshold | Alert Condition |
|---|---|---|
| Delivery success rate | >99.5% | <99% for 5 min |
| p99 delivery latency | <500ms | >2s for 5 min |
| Consumer lag | <1k | >10k for 2 min |
| Retry rate | <1% | >5% for 5 min |
| Connection churn | <5%/hour | >20%/hour |
| Push service errors | <0.5% | >2% for 5 min |
Dashboard sections:
Delivery funnel: emitted → queued → processed → sent → acknowledged
Consumer health: lag per partition, throughput per worker
Client breakdown: WebSocket vs APNs vs FCM vs email success rates
Error distribution: 4xx vs 5xx vs timeouts vs deduped
Runbook: Stopping a Retry Storm
1. Detect: Retry rate > 5% for 5 minutes
2. Immediate mitigation:
- Throttle producers: reduce emit rate by 50%
- Pause non-critical workers: stop email digests, analytics
- Increase retry backoff: 1s → 10s
3. Root cause investigation:
- Check consumer logs for error patterns
- Verify Kafka partition health
- Check push service status (APNs/FCM)
4. Recovery:
- Rehydrate affected clients: force pull from durable log
- Replay missed messages with idempotency keys
- Gradually restore normal rate (10% → 50% → 100%)
5. Postmortem:
- Document timeline, root cause, fix
- Add alert for early detection
- Add chaos test to catch this scenario
The Biggest Scaling Problem Is Usually Not CPU
It is state. Specifically:
connection state
session state
subscription state
unread counters
replay offsets
retry metadata
State synchronization across distributed gateways becomes one of the hardest parts of the architecture.
This is why many systems eventually adopt:
sticky sessions (for WebSocket connections)
consistent hashing (for user→gateway routing)
distributed caches (Redis for session state)
sharded connection registries (per-region user mapping)
Not because developers enjoy complexity. Because real-time infrastructure forces state distribution problems into the open.
Architecture Evolution: Startup → Mid-Scale → High-Scale
Startup (<10k users):
API → WebSocket Server (single instance) → Client
Pros: Simple, fast to build
Cons: Single point of failure, no offline support
When to migrate: When you hit 5k concurrent connections
Mid-scale (10k-100k users):
API → Kafka → Notification Workers → WebSocket Gateway Cluster → Client
↓
Redis (session state)
Pros: Horizontal scaling, offline support, retry logic
Cons: Operational complexity, need for monitoring
When to migrate: When consumer lag consistently >5k
High-scale (100k+ users, multi-region):
API → Kafka (multi-region replication)
↓
Per-user sharded log (user_id → region)
↓
Regional workers → Regional WebSocket gateways → Clients
↓
APNs/FCM (for offline mobile)
↓
Distributed cache (Redis Cluster) for state sync
Pros: Multi-region resilience, per-user ordering, scalable fan-out
Cons: Complex operational overhead, cross-region latency
Key pattern: Shard by
user_idto maintain per-user ordering within region
What Strong Notification Systems Actually Optimize For
Beginners optimize for:
- low latency
Experienced teams optimize for:
correctness
recoverability
observability
idempotency
graceful degradation
Because users tolerate:
- 300ms delay
They do not tolerate:
duplicate payment alerts
missing messages
corrupted counters
inconsistent state
The fastest system is useless if users stop trusting it.
Testing Strategy: Chaos, Load, and E2E
Chaos tests:
Drop connections mid-message
Simulate mobile sleep/wake cycles
Kill consumer workers mid-processing
Inject network latency between regions
Simulate Kafka partition leader elections
Load tests:
Fan-out to 10k users simultaneously
Spike: 100x normal traffic for 1 minute
Sustained: 10k messages/second for 1 hour
Verify consumer lag stays <1k under load
E2E validation:
Weekly automated delivery validation (emit → verify received)
End-to-end tracing for sample notifications (send trace ID through pipeline)
Regular client rehydration tests (disconnect → reconnect → verify no lost messages)
Final Thought
Real-time notification systems look deceptively simple from the outside. But once scale, mobile devices, retries, ordering, distributed state, and reliability requirements enter the picture, they become one of the most complex parts of backend infrastructure.
The hard part is not sending events.
The hard part is guaranteeing that the right user receives the right notification exactly when the system claims they did.