Why Most AI Products Fail to Build Real Technical Moats
Most AI products don’t fail because the AI is weak. They fail because the product has no moat.

In 2026, building an app on top of OpenAI, Anthropic, or another foundation model is easier than ever. But ease of building is not the same as defensibility. A polished UI, a clever prompt, and a few RAG pipelines can get you to launch, but they rarely get you to lasting advantage.
The uncomfortable truth is simple: OpenAI API ≠ competitive moat.
Why wrappers exploded
The first wave of AI startups was inevitable. Foundation models became powerful enough that developers could ship useful products without training models from scratch. That lowered the barrier to entry dramatically.
So naturally, the market filled up with wrappers.
That was not irrational. It was the fastest way to test demand, validate workflows, and prove that people would pay for AI-enabled outcomes. For many founders, a wrapper was the right starting point because it reduced time-to-market and let them focus on distribution.
But what was good for speed was bad for defensibility.
Why wrappers are fragile
A wrapper around an LLM is often just a thin interface over someone else’s intelligence. If the underlying model improves, your product advantage shrinks. If a competitor copies your UX, your edge disappears. If the model provider ships your core feature natively, your differentiation collapses.
This is the core problem: the closer your product is to a generic interface over a foundation model, the easier it is to clone.
There are three reasons this matters:
- The UI is visible and easy to imitate.
- The prompts and workflows are often not deeply proprietary.
- The core model capability is rented, not owned.
That means many AI products are competing on packaging rather than infrastructure.
A good way to think about this is: if your product can be described as “ChatGPT, but for X,” you probably have product-market fit risk before you have moat.
What creates real moat
A real moat in AI is usually not “we use GPT.” It comes from owning something the next startup cannot easily replicate.
That can be:
- Proprietary data.
- Embedded workflows.
- Deep enterprise integration.
- Distribution advantages.
- Domain-specific expertise.
- Feedback loops that improve the product over time.
The important distinction is this: model access is replaceable, but workflow capture is sticky.
If your product becomes part of how a team actually works, not just a tool they try once, you start building defensibility. If you own the system of record, the approval flow, the compliance layer, or the operational pipeline, you are no longer just selling AI — you are selling infrastructure.
A useful rule of thumb: the more your product learns from user behavior, customer data, and domain-specific outcomes, the harder it becomes to copy.
Moat patterns
There are a few moat patterns that tend to survive model commoditization better than a pure UI layer.
Proprietary data moat
This is the most obvious one. If your product collects high-signal, domain-specific data that competitors can’t easily access, you can improve faster over time.
Examples include:
- labeled support cases,
- medical annotations,
- legal review outcomes,
- sales conversation feedback,
- codebase-specific assistant traces.
The strength of this moat depends on whether the data is merely collected or actually turned into better predictions, better retrieval, or better workflow decisions.
Workflow moat
This is often stronger than people think. If your product becomes the place where work starts, gets reviewed, and gets approved, switching becomes painful.
Workflow moats usually require:
- native integrations,
- permissions and access control,
- human-in-the-loop steps,
- audit logs,
- and reliable outputs that fit existing processes.
This is why enterprise AI products often win by becoming infrastructure, not just assistants.
Distribution moat
Sometimes the moat is not technical first, but technical plus distribution. If your product is embedded in Slack, email, CRM, IDEs, or internal tooling, it becomes harder to displace because adoption is already inside the user’s daily flow.
Distribution matters because the best model in the world still loses if users never reach it.
Trust and compliance moat
In regulated environments, trust is product value.
If you can prove:
- data handling,
- retention rules,
- access controls,
- auditability,
- and predictable behavior,
you are competing on more than output quality. For many enterprise buyers, that is the difference between a demo and a contract.
Cost and infrastructure moat
Some AI products can create an advantage by reducing inference cost, latency, or operational overhead at scale.
This moat is weaker than proprietary data or workflow lock-in, but it matters when usage volume is high. If you can deliver similar quality at lower cost, your margin profile improves and your pricing flexibility increases.
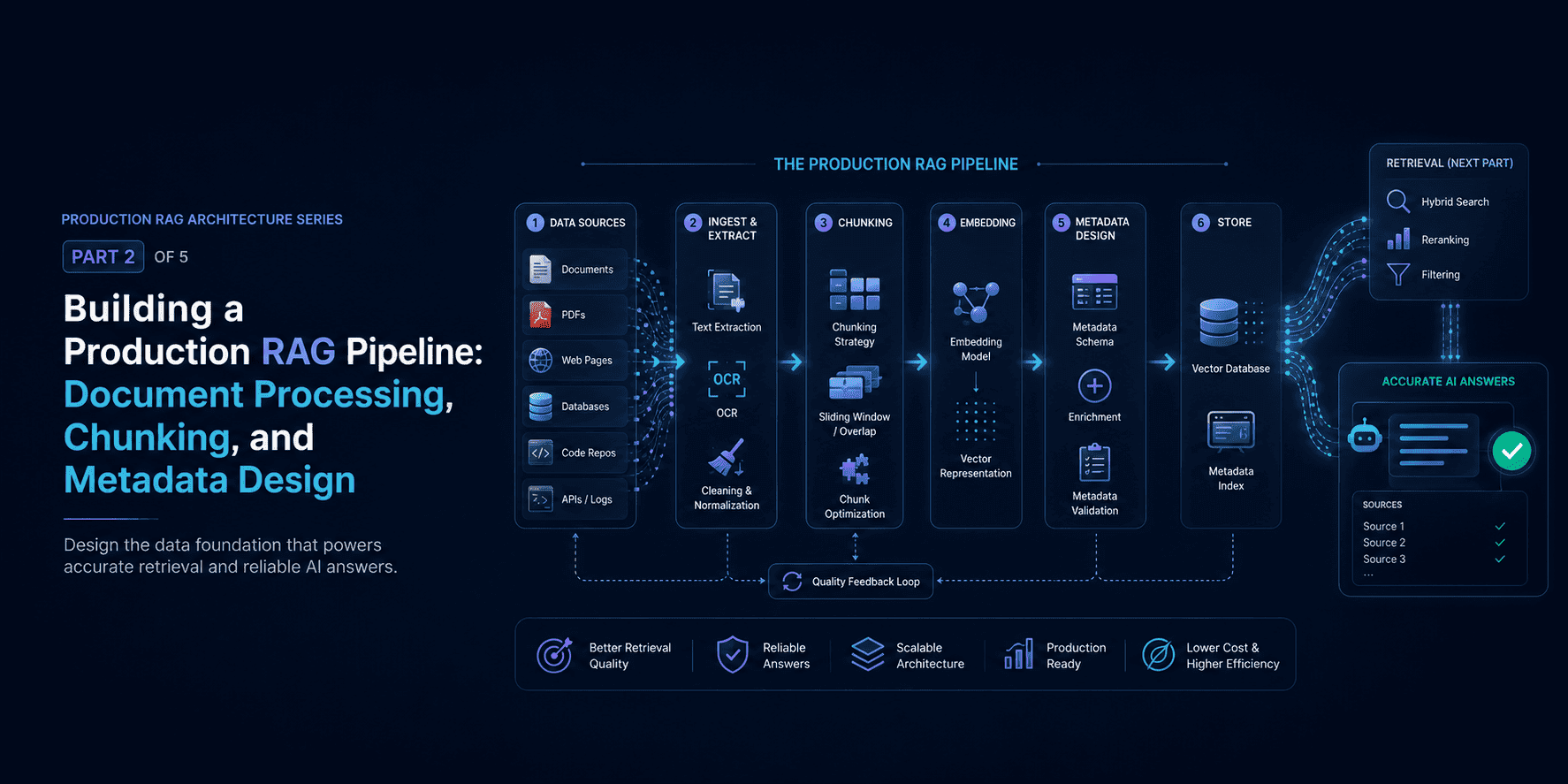
Why RAG alone is not enough
RAG is useful, but it is not a moat by itself.
Retrieval helps connect foundation models to private corpora, internal docs, and customer-specific context. But if every competitor can index similar documents and call the same model, the architecture is not automatically defensible.
RAG becomes valuable when it is paired with:
- proprietary corpora,
- strong ranking and retrieval quality,
- feedback loops,
- and domain-specific evaluation.
The moat is not the retrieval layer alone. It is the combination of retrieval, data quality, and embedded usage over time.
Dependency risk on OpenAI
One of the biggest hidden risks in AI startups is platform dependency.
If your roadmap depends on a single provider, you inherit their pricing, latency, policy changes, rate limits, and feature roadmap. That is not a moat. That is a liability.
When OpenAI improves a capability, it can help the whole market, including your competitors. When OpenAI ships a built-in feature that overlaps with your product, your differentiation can evaporate overnight.
This is why relying entirely on external model APIs is dangerous for long-term architecture. The more your product is just a front-end to a general model, the more exposed you are to commoditization.
A startup should always ask: if model prices change, if output quality improves, or if the model vendor ships our core feature natively, what still makes us valuable?
Enterprise workflows matter
The strongest AI products usually do something more specific than “answer questions.” They solve a workflow that already exists inside a company.
Enterprise buyers care about more than output quality. They care about:
- Access control.
- Compliance.
- Auditability.
- Data retention.
- Integrations with existing systems.
- Human approval steps.
- Reliability at scale.
That is why workflow-based products tend to have stronger moats than generic assistants. They don’t just generate text. They become part of operational machinery.
Once AI is embedded in billing, support, procurement, legal review, or internal knowledge systems, switching costs rise quickly.
This is also why the best products often feel “boring” from the outside. They are not flashy consumer apps; they are operational systems that quietly save time, reduce risk, or increase throughput.
Vertical AI wins
Vertical AI is often stronger than horizontal AI because it can combine domain data, workflow design, and distribution in one package.
A vertical product knows the problem deeply. It understands terminology, edge cases, compliance rules, and customer expectations in a specific domain. That makes it harder to replace with a generic chatbot or a broad copilot.
This is where proprietary data becomes especially important. The more your product learns from a narrow, high-value domain, the more its quality becomes tied to data that others do not have.
In practice, the winners are often the companies that can connect three things:
- domain-specific data,
- operational workflow,
- and recurring business value.
A good vertical AI product is not just “smart.” It is deeply fitted to a single job, and that fit becomes harder to copy with every interaction.
Which AI companies survive
The AI companies most likely to survive are not necessarily the ones with the flashiest demos. They are the ones that turn model capability into durable product advantage.
In practice, that means companies that:
- own proprietary or hard-to-access data,
- sit inside critical workflows,
- integrate deeply into enterprise systems,
- build operational infrastructure, not just interfaces,
- and create switching costs through usage, trust, and process.
The model may be replaceable. The product around it should not be.
That is the difference between a temporary AI app and a lasting business.
How to measure moat
If you are building an AI product, here are a few signals that the moat is getting stronger:
- Retention stays high even when model quality changes.
- Customers rely on the product as part of a repeatable workflow.
- The cost to replicate your dataset is high.
- More value comes from your proprietary layer than from the base model.
- Integrations increase switching costs over time.
- Unit economics improve as usage and feedback grow.
A simple test is this: if a competitor copied your UI tomorrow, would they still need the same data, trust, integrations, and operational context to match your product?
If the answer is yes, you are probably building a real moat.
Conclusion
The problem with most AI products is not that they use AI. It is that they confuse access to AI with defensibility.
A great interface can get attention, but it rarely creates a moat by itself. Real technical moats come from data, workflow, infrastructure, and integration — the things that are hard to copy and even harder to unwind.
If you are building in AI, the right question is not “How can we add a model?” The right question is: What do we own that becomes more valuable over time?
The best AI companies will not be the ones with the loudest demo. They will be the ones whose product gets more embedded, more trusted, and more expensive to replace every quarter.